
Toolathlon-GYM: Large-Scale Long-Horizon Environments for Tool-Use Agents
503 multi-tool tasks backed by a local PostgreSQL database — no external APIs required

Training and evaluating LLM agents on real-world tool use is hard. Most existing datasets are either too narrow in tool coverage, too small in scale, or depend on live external APIs that change over time. We introduce Toolathlon-GYM, a large-scale, self-contained environment with 503 tasks, 25 MCP servers, and a rich mock database. It runs entirely locally, with no external API calls required at evaluation time.
Toolathlon-GYM is built on and extends the infrastructure from Toolathlon by HKUST-NLP. The task format, evaluation framework, MCP server interfaces, and database schema design all originate from the Toolathlon project. This dataset applies the same format at larger scale, producing a substantially bigger and more diverse task pool for training and evaluation. Each task asks an agent to complete an end-to-end goal such as pulling data from a mock enterprise database, producing a spreadsheet report, scheduling a calendar event, and sending a summary email, using a fixed set of MCP (Model Context Protocol) servers as tools.
Every task is fully automated: a preprocess/main.py script sets up the initial workspace state before the run, the agent executes using the provided tools, and an evaluation/main.py script checks the outputs against reference groundtruth. No human graders or live external services are involved.
The dataset is designed to stress-test agent capabilities that matter in practice: multi-step planning across heterogeneous tools, reading and writing structured file formats, cross-system data synchronization, and long-horizon task completion under a fixed step budget. We also provide an example agent built with the CAMEL-AI framework for running in the Toolathlon-GYM environments.
Task structure
All 503 tasks live in tasks/finalpool/. Each task directory follows a consistent layout:
<task-name>/
├── task_config.json # Which MCP servers the agent can use
├── docs/
│ ├── task.md # Task description shown to the agent
│ └── agent_system_prompt.md
├── evaluation/main.py # Automated evaluator
├── preprocess/main.py # DB state setup (run automatically before each task)
├── initial_workspace/ # Input files pre-loaded into the agent workspace
└── groundtruth_workspace/ # Reference outputs for evaluation
Task descriptions (task.md) are written without tool or service brand names — references to tools like "Notion", "Google Calendar", or "Canvas" are obfuscated with generic descriptions such as "knowledge base", "shared calendar", or "learning management system". This is the same obfuscation convention used by the original Toolathlon project, and prevents agents from taking shortcuts based on keyword recognition, encouraging genuine tool-use reasoning.
The mock database
Connection: toolathlon_gym @ localhost:5432 (user: eigent, password: camel)
All data is served from a local PostgreSQL database, initialized from a compressed dump (db/init.sql.gz, 8.2 MB). No external API calls are made at runtime. This makes the environments fully controllable and avoids issues with API rate limits, schema changes, or data drift.
Data is derived from or simulated after real-world sources: Kaggle OULAD (Open University Learning Analytics Dataset) for Learning Management System data, Kaggle HR Analytics for enterprise HR data, Yahoo Finance API for financial data, and a combination of Kaggle Amazon product datasets and DummyJSON for e-commerce data.
Data-rich schemas
| MCP Database | Description | Scale |
|---|---|---|
| canvas | Learning Management System — courses, users, enrollments, assignments, submissions, quizzes, rubrics, announcements | 22 courses, 28,865 users, 32,663 enrollments, 206 assignments, 173,912 submissions, 77 quizzes |
| snowflake | Enterprise data warehouse — HR analytics, sales, and support center domains | 50,000 employees, 20,000 sales orders, 31,588 support tickets |
| woocommerce | E-commerce — products, orders, customers, coupons, reviews, shipping zones, tax rates | 82 products, 150 orders, 50 customers, 396 reviews |
| yahoo_finance | Stock market — prices, financial statements, news, options, holders | 50 tickers, 3,510 price records |
| youtube | Video platform — channels, playlists, videos, transcripts | 3 channels, 2 playlists, 135 videos |
| train | Rail system — stations, trains, routes, seats | 8 trains, 16 routes |
Dataset statistics
Total: 503 tasks
MCP count distribution
Tasks range from 4 to 8 MCP servers, with the majority requiring 4–7 tools. A higher MCP count indicates greater cross-system coordination is required: agents must orchestrate more heterogeneous tools within a single task, plan longer action sequences, and handle more complex data flows across services:
| MCPs per task | Number of tasks |
|---|---|
| 4 | 123 |
| 5 | 133 |
| 6 | 105 |
| 7 | 126 |
| 8 | 16 |
Below are representative examples from each tier, illustrating how task complexity and coordination demands scale with MCP count. (Because the original text is too long, only an abstract of the task is shown here.)
4 MCPs — wc-customer-retention-email (woocommerce, excel, emails, filesystem)
Identify the top 10 customers from the online store by total amount spent. Create an Excel spreadsheet called
VIP_Customer_Report.xlsxwith columns Rank, Name, Email, Orders_Count, and Total_Spent sorted from highest to lowest. Then send a personalized thank-you email to each of these 10 customers fromvip-program@store.example.com, addressing them by first name and mentioning their total spending amount.
5 MCPs — 12306-beijing-shanghai-trip-notion-gcal-word (rail_12306, notion, google_calendar, word, emails)
Plan a same-day round trip between Beijing and Shanghai. Query available high-speed trains on March 10, 2026 in both directions and select the best outbound and return trains based on timing. Record the trip details in the team knowledge base, create a
Travel_Plan.docxwith three sections (Outbound Journey, Return Journey, Booking Summary), add two calendar events covering the travel windows, and send a confirmation email totravel@consulting.com.
6 MCPs — arxiv-conference-prep (scholarly, arxiv-latex, pptx, google_calendar, emails, filesystem)
Prepare for the RLHF Summit 2026 conference. Search for at least 5 papers about reinforcement learning from human feedback, then read their full LaTeX source to extract methodology details. Create a PowerPoint presentation with a title slide, an overview of the RLHF field, one slide per paper, and a synthesis slide. Add a calendar event for the conference on April 10, 2026 and email preparation materials to collaborators.
7 MCPs — arxiv-research-pipeline-notion-excel (scholarly, arxiv_local, terminal, excel, notion, filesystem)
Build a research knowledge base on large language models. Search for papers on LLMs, prompt engineering, and in-context learning. Use the terminal to run a synthesis script that reads paper metadata and contents, calculates relevance scores, and outputs a structured JSON summary. Create an Excel file with three sheets (Paper_Catalog, Method_Comparison, Research_Gaps) and a Notion page titled "LLM Research Hub" containing a research dashboard with landscape overview, methodology comparison, and identified gaps.
8 MCPs — arxiv-research-workflow-pipeline (scholarly, arxiv-latex, terminal, word, google_calendar, emails, pdf-tools, filesystem)
Establish a literature review pipeline that begins by searching for recent papers on neural network architectures and downloading their PDFs. Parse the LaTeX source files of these papers to extract key mathematical formulations and organize them into a structured format. Based on the collected materials, build a categorized bibliography with proper academic citations. Then produce a 2,000-word research summary that synthesizes major trends, identifies research gaps, and outlines potential future directions. Finally, schedule a team review meeting, send calendar invitations with the summary document attached, and store all working files in a centralized location for collaboration and future reference.
MCP server coverage
25 MCP servers are available across the dataset, spanning file input/output, data warehouses, productivity tools, web interaction, and domain-specific APIs. The table below shows how many tasks include each server, giving a sense of which tool categories are most heavily represented in the environment:
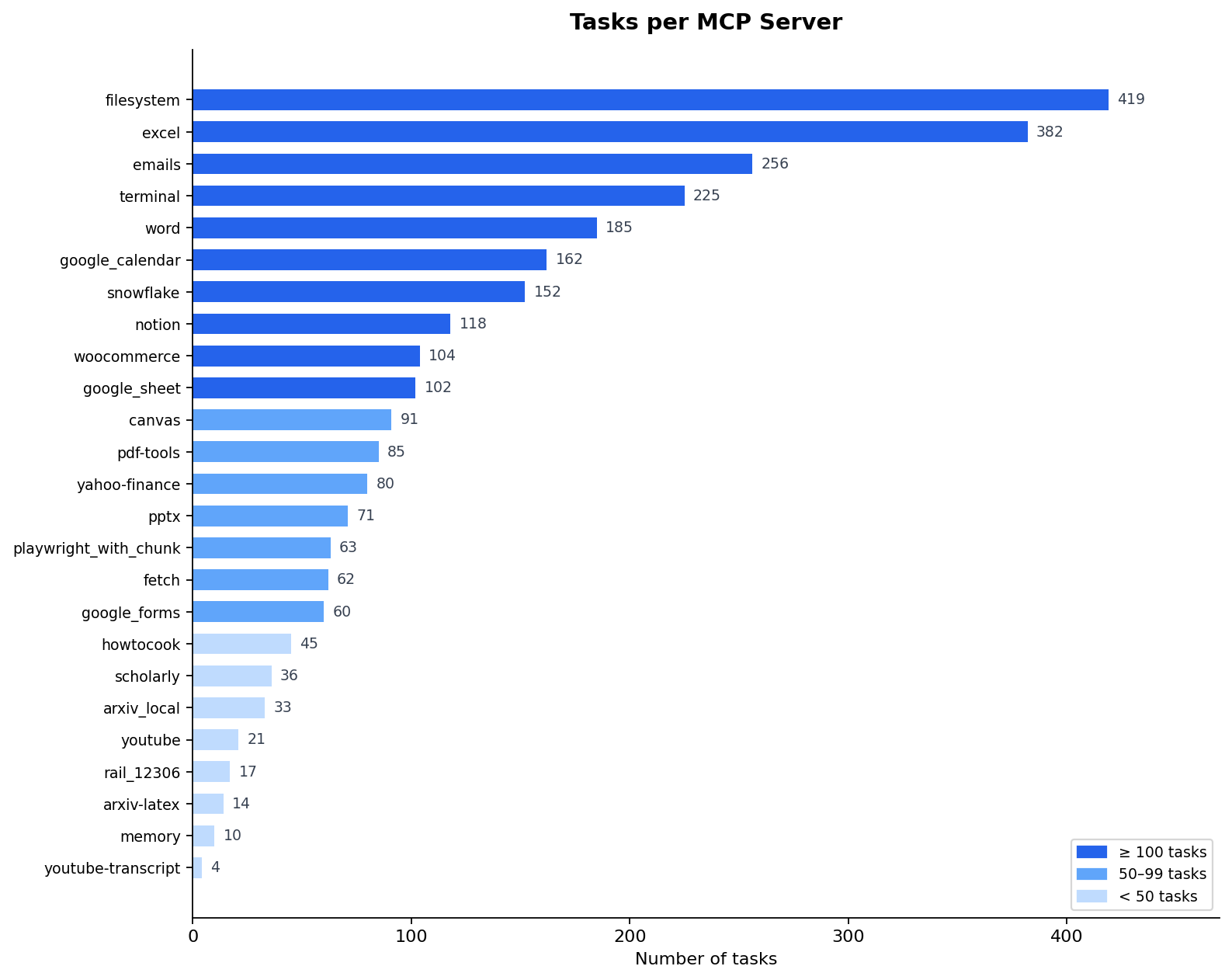
The most frequently used servers reflect the output-heavy nature of the tasks. filesystem appears in nearly every task as the agent's workspace for reading input files and writing results. excel and emails are the two most common output channels — most tasks produce at least one structured spreadsheet and send a summary message. terminal requires the agent to write and execute code scripts for data transformation or statistical analysis that cannot be handled by other tools alone.
snowflake is the primary data source for enterprise workflow tasks, exposing three domains: HR analytics (50,000 employees, salary, performance ratings, and tenure data), sales (20,000 orders across regions and customer segments), and customer support (31,588 tickets with SLA and resolution metadata). Tasks typically query one or two domains, compute aggregations or flag outliers, and write results to Excel or Word. canvas similarly anchors LMS tasks, with agents filtering submissions by course, computing grade distributions, or flagging at-risk students from a dataset of 22 courses and 173,912 submissions.
playwright_with_chunk and fetch both retrieve data from mock local servers — playwright tasks scrape HTML pages (e.g. competitor profiles or product listings), while fetch tasks call REST API endpoints (e.g. industry salary datasets or inventory forecasts) and join the results with data warehouse records. google_forms tasks go a step further: the agent creates a structured survey programmatically, then queries order or enrollment data to identify the right recipients and sends personalized invitations.
howtocook exposes a recipe and nutrition database used for catering, meal planning, and nutrition analysis tasks. pdf-tools appears both as a reader (reference PDFs supplied as input) and a writer (formatted reports generated as output). memory enables multi-round research tasks where the agent must track search progress across iterations and avoid re-querying data it has already retrieved. youtube-transcript extracts raw transcript text from video recordings, which the agent then processes to produce structured documents or surveys.
Initial Workspace File Types
Initial workspace file types provided to the agent at task start span 11 distinct formats, covering the full range of documents an agent would encounter in real enterprise workflows. The distribution reflects realistic task composition: Markdown briefs and PDF reference documents are most common, followed by structured data formats like JSON and Excel that agents must read, transform, and write back:
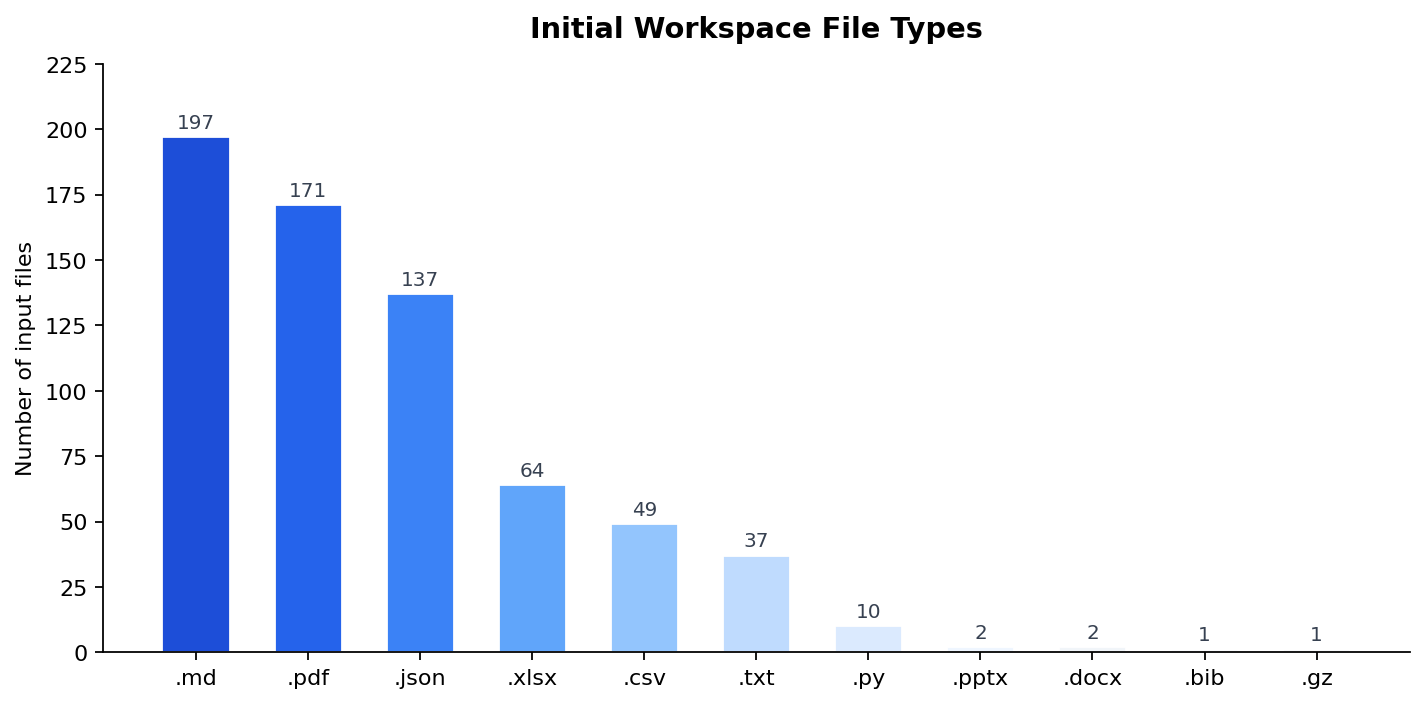
Here is a breakdown of the most representative file types found in the initial workspace:
Markdown (.md) files are the most common input, serving as task briefs, operational guides, and planning templates — e.g. travel_guide.md (company travel policy for a rail booking task), analysis_methodology.md (statistical approach for a sales analysis), or Research_Scope.md (topic boundaries for a literature review).
PDF (.pdf) files are reference documents the agent must parse before acting — compensation policies, portfolio guidelines, assessment rubrics, or audit procedures whose content directly determines the correct output. JSON (.json) files carry parameterized configuration: trip settings, filter thresholds, audit criteria, budget caps, and team rosters that let tasks be varied without changing the task description.
Excel (.xlsx) inputs are pre-filled templates with predefined column headers the agent must populate (e.g. paper_notes_template.xlsx, approved_budget.xlsx). CSV (.csv) files carry tabular reference data the agent joins against database results — industry salary datasets, portfolio holdings, faculty directories, or supplier contact lists. Text (.txt) files supply lightweight structured content: lists of paper IDs to download, email body templates, quarterly sales targets, or escalation policy rules.
Python (.py) scripts are starter templates the agent completes and executes via the terminal, testing its ability to read existing code, infer intent, and integrate script output into a larger workflow. The rarer formats each serve a specific role: .pptx inputs are existing slide decks the agent extends rather than creates from scratch; .docx inputs are document skeletons with predefined headings to populate; the single .bib file is a seed bibliography the agent augments with newly discovered papers; and the single .gz archive must be unpacked with the terminal before its contents can be used.
What makes Toolathlon-GYM different
Scale and diversity
At 503 tasks across 25 MCP servers and 6 data domains, Toolathlon-GYM is substantially larger and more tool-diverse than earlier datasets in this space. Tasks are designed to require genuine cross-system coordination rather than single-tool lookups.
Fully local and reproducible
The entire environment runs from a single Docker Compose file. No API keys for data services are needed at evaluation time. The PostgreSQL dump is versioned and deterministic, so results are reproducible across machines and over time.
Realistic task complexity
Tasks are drawn from real enterprise workflow patterns: pulling data from an HR database to produce a salary analysis spreadsheet, cross-referencing Learning Management System submission records against calendar deadlines, generating slide decks from scraped web data, and similar multi-step goals. Most tasks require 4–7 tools to complete correctly.
Acknowledgements
Toolathlon-GYM is built on the infrastructure and original data pipelines from:
Toolathlon: Benchmarking LLM Agents on Real-World Tool-Use Tasks HKUST-NLP https://github.com/hkust-nlp/Toolathlon
The mock database schema design, MCP server interfaces, and task evaluation framework originate from the Toolathlon project. This dataset extends the original with additional tasks and larger-scale mock data.
Citation
If you use Toolathlon-GYM in your research, please cite:
@misc{toolathlon-gym,
author = {Puzhen Zhang and Weijie Bai and Wendong Fan and Guohao Li},
title = {{Toolathlon-GYM: Large-Scale Long-Horizon Environments for Tool-Use Agents}},
year = {2026},
url = {https://github.com/eigent-ai/toolathlon_gym}
}
Contact
If you would like to get in touch, please contact info@eigent.ai
Recent Posts

Best Legal AI Agents in 2026: Top Platforms Compared (+ a Free Alternative)
The best legal AI agents in 2026 compared: Harvey, CoCounsel, Lexis+ Protégé, Kira, and Spellbook — plus Eigent, the free, open-source legal AI you can self-host.

CoCounsel Alternative (Free & Open Source): Why Teams Choose Eigent
Looking for a free CoCounsel alternative? Compare CoCounsel Legal with Eigent, the open-source legal AI platform you can self-host, plus a full contract workflow.

Eudia Alternative (Free & Open Source): Why Teams Choose Eigent
Looking for a free Eudia alternative? Compare Eudia's augmented intelligence platform with Eigent, the open-source legal AI you can self-host, plus a full workflow.